ROS机器人设计参考.

1.硬件总体设计
做硬件,首先要确定一下小白机器人的核心CPU,有近些年火热的ESP32和昂贵的Linux SOC两种选择,最终还是选择了能跑Linux的RK3566芯片,虽然价格昂贵、功耗高、发热重、体积大,但是在Linux系统下编程更加自由,功能更加容易扩展,有大量的开源项目可供使用,不必自己重新造轮子,例如下文中会提到的强大的ros系统。 确定了处理器之后,机器人上肯定少不了一块液晶屏,为的是和用户进行人机交互,显示个表情包啥的,提供必要的情绪价值。 要想让机器人能看见这个世界,必须需要安装一个摄像头;要机器人能听会说,麦克风和扬声器也是必须要的;要实现机器人能走路,最简单的方式就是安装两个差速轮,并且为了支持它到处跑,电池供电也是必不可少的。 另外为了机器人在室内环境中能够避障和导航,我还为小白机器人的顶部配备了单线激光雷达;为了实现机器人常见的离线命令词控制,内置了离线语音芯片;为了实现待机充电,在机器人内部做了电源切换和充电电路。
1.软件整体框架
(1)ROS系统简介
ROS(机器人操作系统,Robot Operating System),是专为机器人软件开发所设计出来的一套电脑操作系统架构。小白机器人的软件在ROS框架下构建,需要掌握ROS基本的命令行工具、可视化工具、工程编译方法、ROS Launch文件、C++和Python语言等ROS开发基础。
推荐ROS入门课程:
ROS官方教程 https://wiki.ros.org/cn
古月居GYH 【古月居】古月·ROS入门21讲 一学就会的ROS机器人入门教程
机器人工匠阿杰 机器人操作系统 ROS 快速入门教程
ROS包括了通信机制、开发工具、应用功能和生态系统四个部分:

ROS的通信机制主要有Topic、Service、Action三大方式,最常用的是Topic:
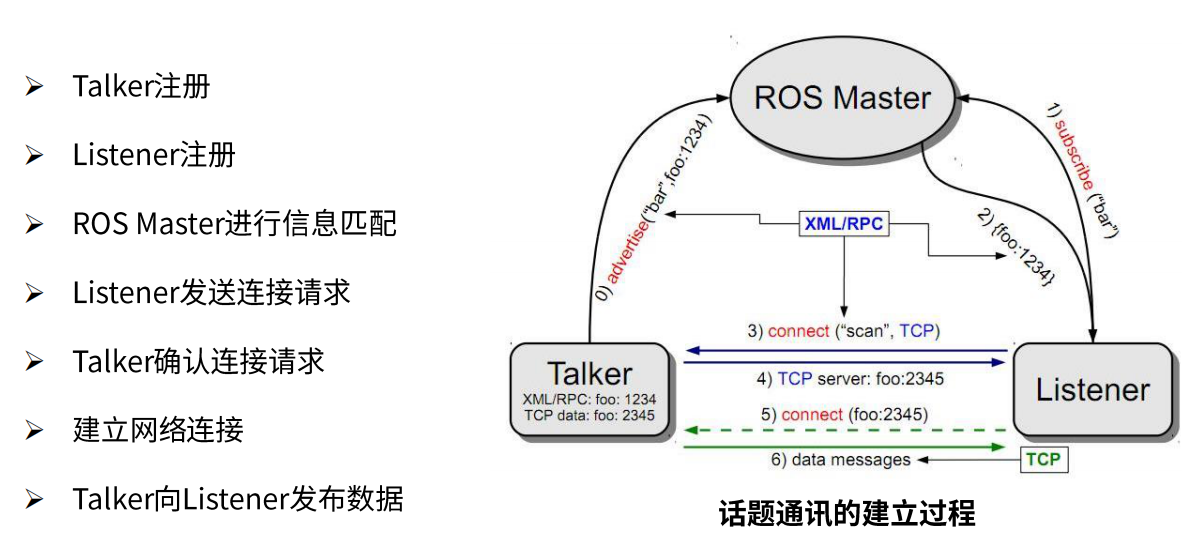
ROS常用的可视化工具有rviz、rqt、rqt_image_view、rqt_graph、rqt_plot等,ROS主要应用于移动机器人底盘(SLAM、NAV)、机械臂(MoveIt)和底盘与机械臂结合的复合机器人。

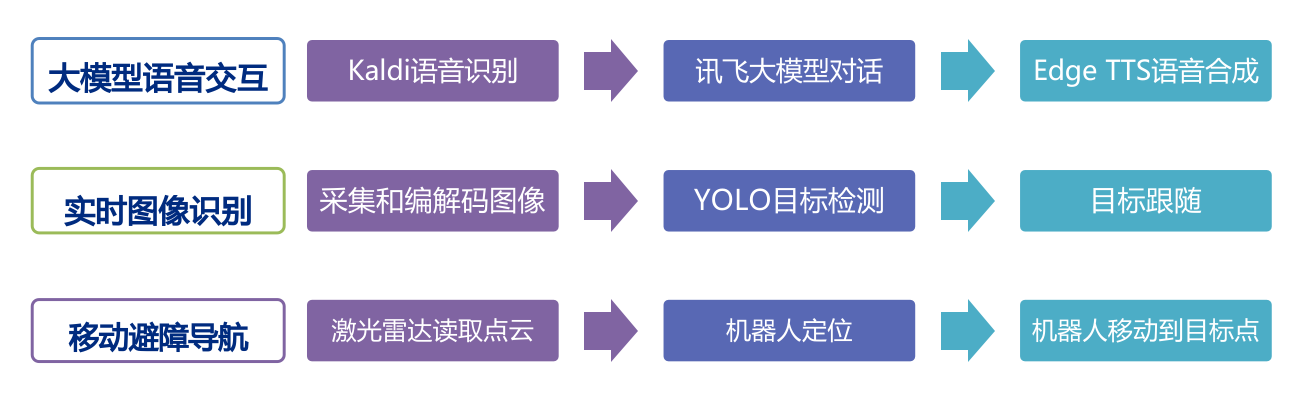
(2)本系统的主要软件功能
这是本项目的三大主要软件功能,包括了语音交互、图像识别、移动导航。
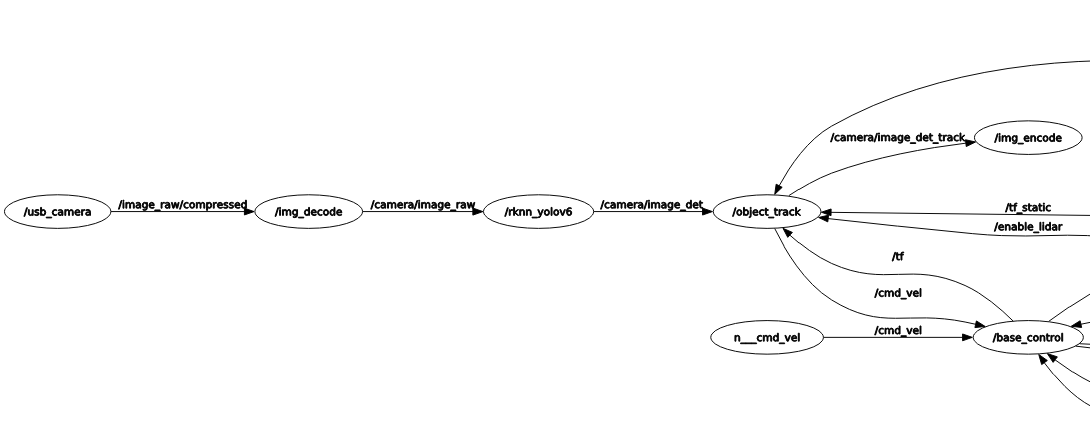
(3)本系统的ROS节点图
左侧是图像的采集处理流程,先读取USB相机原始的JPEG格式数据,然后解码和缩放,送入yolov6处理模块,处理得到检测框和绘制了检测框的图像,然后送入跟踪模块,得到绘制了跟踪结果的图像,最后送到JPEG编码节点,发布出去方便电脑或手机接收查看。
注意这里的解码、缩放以及最后的编码都是调用了RK3566的硬件编解码能力,而yolov6使用了RK3566 RKNN的AI加速能力。
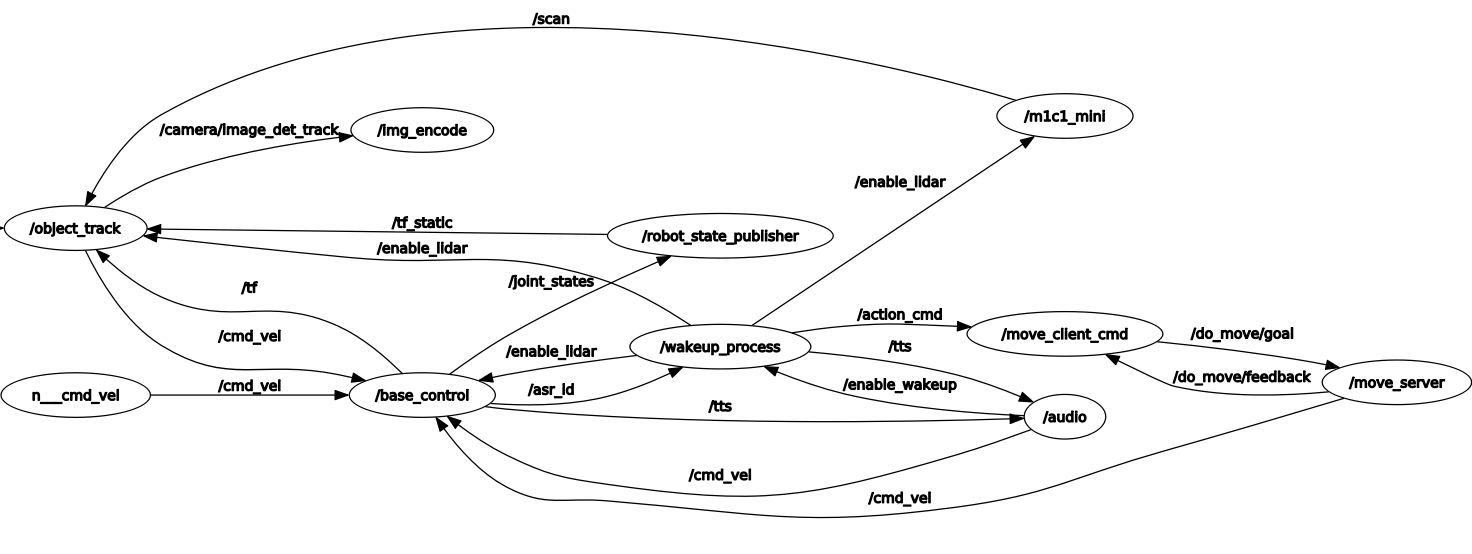
右侧是其他处理流程,包括了底盘控制节点base_control,雷达驱动节点/m1c1_mini,离线唤醒命令处理节点wakeup_process,纯python编写的语音处理节点audio,精确移动和旋转命令执行节点/move_client_cmd和/move_server。下文会对核心的几个节点做简单介绍。
2.底盘控制节点
base_control节点的主要功能:和STM32串口通信,计算并发布里程计/odom和/tf,发布电池信息话题,发布离线语音命令ID;订阅速度话题转换为串口命令,订阅雷达使能话题转换为串口命令,订阅位置复位话题清零位置等。
(1)和STM32的通信协议
底盘控制节点(base_control)每20ms都会通过串口从STM32接收到机器人的一些底层状态信息,包括了当前20ms内的编码器的脉冲数,电池电压,充电状态,离线语音命令ID;底盘控制节点每20ms都会向STM32发送控制命令,包括了两个轮子的PWM占空比,是否打开雷达电源。具体的通信协议如下:
#pragma pack(1)
typedef struct
{
unsigned char head1;//数据头1 'D'
unsigned char head2;//数据头2 'A'
unsigned char struct_size;//结构体长度
short encoder1;//编码器当前值1
short encoder2;//编码器当前值2
short vbat_mv;//电池电压 mV
unsigned char charger_connected;//是否连接充电器
unsigned char fully_charged;//是否充满电
unsigned char asr_id;//语音命令ID
unsigned char end1;//数据尾1 'T'
unsigned char end2;//数据尾2 'A'
unsigned char end3;//数据尾3 '\r' 0x0d
unsigned char end4;//数据尾4 '\n' 0x0a
}McuData;
typedef struct
{
unsigned char head1;//数据头1 'D'
unsigned char head2;//数据头2 'A'
unsigned char struct_size;//结构体长度
short pwm1;//油门PWM1
short pwm2;//油门PWM2
unsigned char enable_power;//开启5V雷达电源
unsigned char end1;//数据尾1 'T'
unsigned char end2;//数据尾2 'A'
unsigned char end3;//数据尾3 '\r' 0x0d
unsigned char end4;//数据尾4 '\n' 0x0a
}CmdData;
#pragma pack()
(2)差速机器人的运动学模型
小白机器人采用两个差速轮加上一个万向球的底盘架构,差速机器人的运动学模型如下:
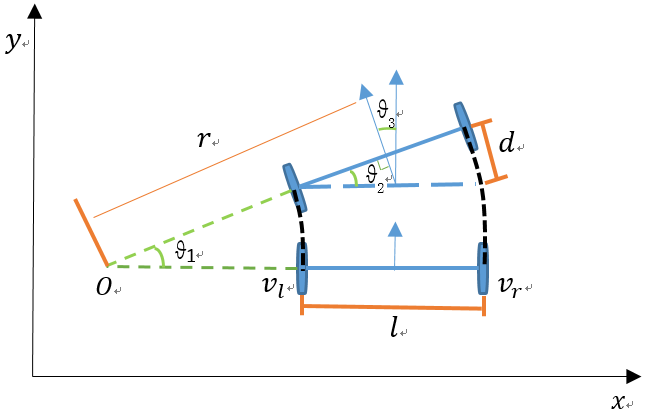
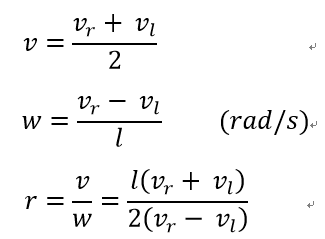

代码实现:
//v = (vr+vl)*0.5
//w = (vr-vl)/ l(轮距)
double delta_m = (double)(mcu_data.encoder2 + mcu_data.encoder1) * 0.5 / pluses_m;// 当前周期的脉冲数均值 / pluses/m = 距离m
double delta_rad = (double)(mcu_data.encoder2 - mcu_data.encoder1)/wheel_distance_m / pluses_m;// 当前周期的脉冲数差值 / pluses/m / 轮距 = 角度rad
//vl = v - w*l(轮距)*0.5
//vr = v + w*l(轮距)*0.5
//速度转换为编码器目标值
int target1 = (target_m_s - target_rad_s * wheel_distance_m *0.5) * dt * pluses_m;//左轮速度m/s * dt * pluses/m = 左轮距离m * pluses/m = 左轮脉冲数
int target2 = (target_m_s + target_rad_s * wheel_distance_m *0.5) * dt * pluses_m;//右轮速度m/s * dt * pluses/m = 右轮距离m * pluses/m = 右轮脉冲数
(3)PID控制机器人速度
PID控制分为两种,位置式PID和增量式PID:
位置型PID:控制输出与整个历史误差有关,包括比例项、积分项(误差的累加值)和微分项。这种算法直接计算出控制量的绝对值。
增量型PID:控制输出仅与当前误差及前几次误差的差值有关,计算的是控制量的增量,即每次调整的量,而不是控制量的绝对值。因此,它没有积分累加的概念。
优缺点如下:
位置式PID:直接基于当前误差控制输出,更适合精确的位置或速度控制,但可能会遇到积分饱和问题。
增量式PID:基于误差变化量控制输出,通常实现更简单,适合在对误差变化快速响应的场合,能较好地避免积分饱和。
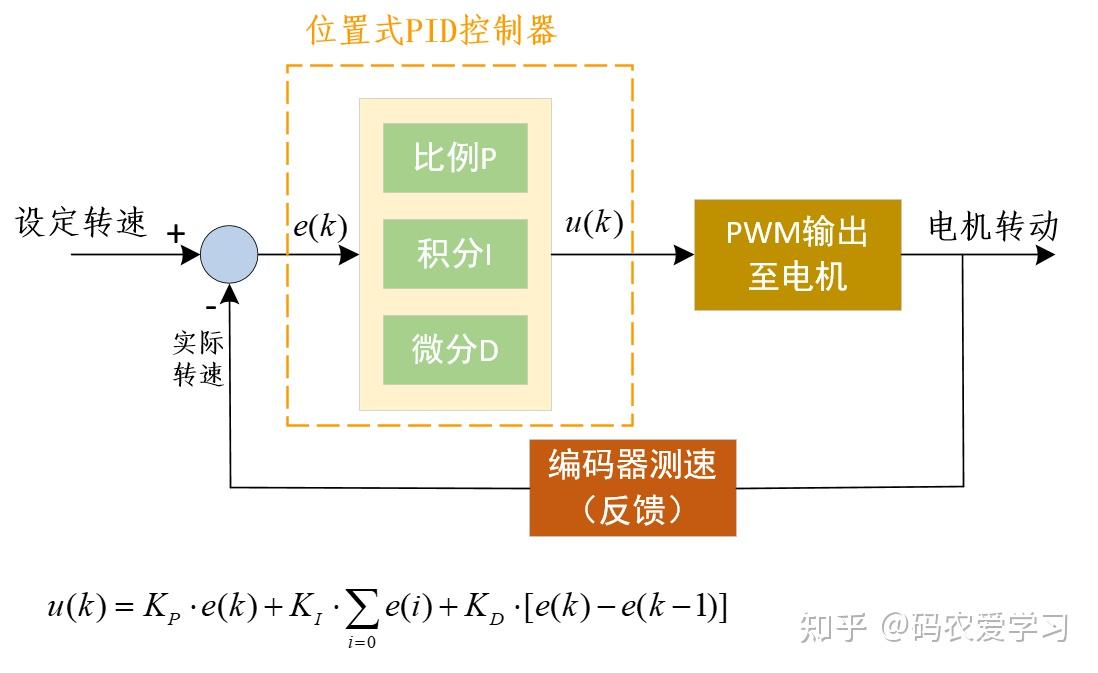
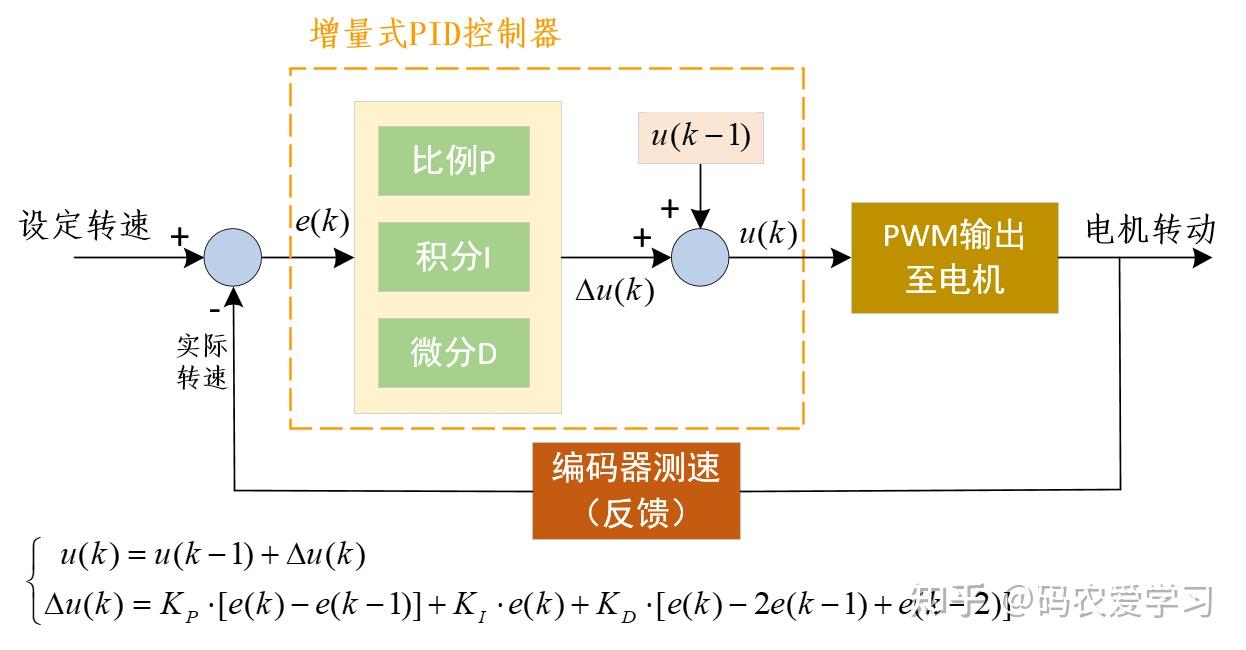
为了达到更高的速度控制精度,小白机器人采用位置式PID控制电机速度。
PID参数调节参考链接:
电机控制进阶——PID速度控制:https://zhuanlan.zhihu.com/p/373402745
在ROS系统下可以使用rqt_reconfigure和rqt_plot工具来调节和可视化PID控制效果:
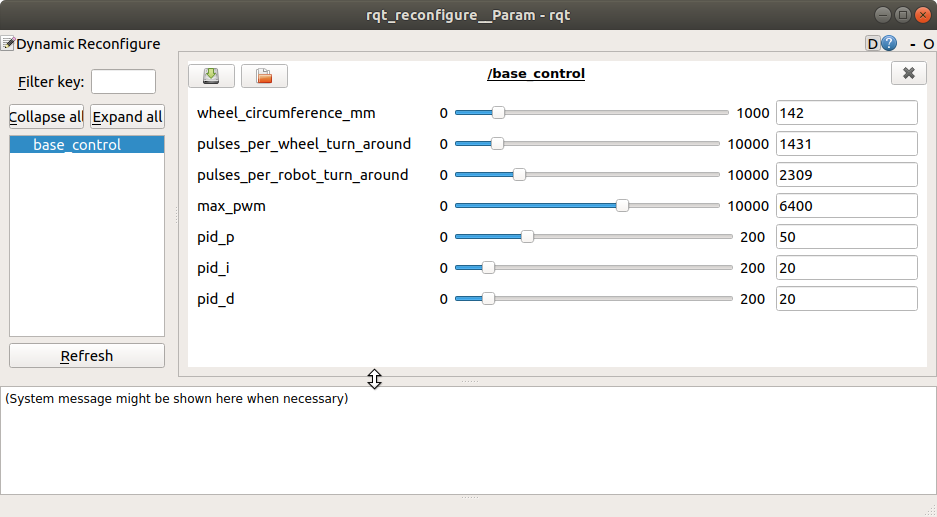
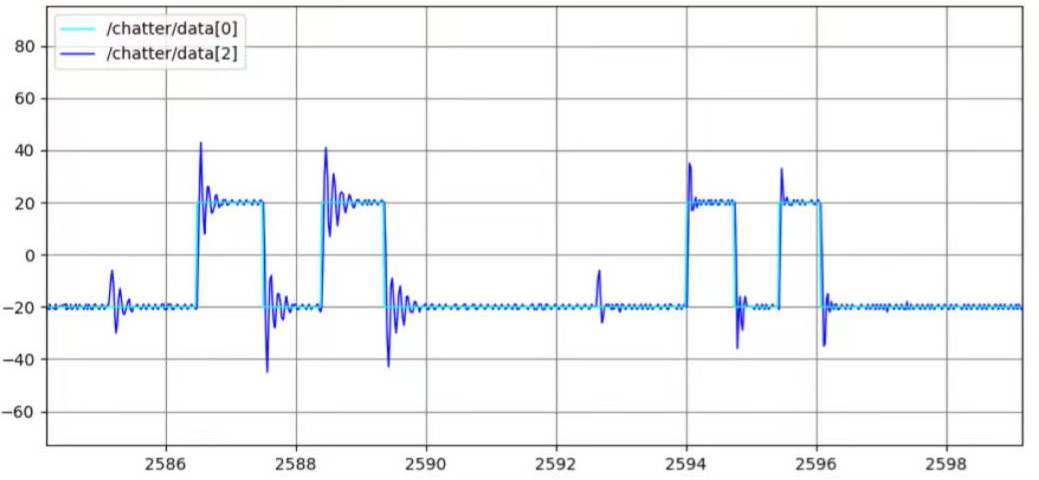
位置式PID控制器的代码如下:
#include "pid.h"
void init_pid(PidController* pid,double Kp,double Ki,double Kd)
{
pid->Kp = Kp; // 比例系数
pid->Ki = Ki; // 积分系数
pid->Kd = Kd; // 微分系数
pid->integral = 0; // 误差累计
pid->last_error = 0; // 上一次误差
pid->output = 0; //输出值
}
// 计算PID控制器输出
double calculate_pid_output(PidController* pid,int target,int encoder,int max_pwm)
{
// 计算误差
double error,error_rate;
error = target - encoder;
// 计算误差变化率
error_rate = error - pid->last_error;
// 计算误差累计
pid->integral += error;
if(pid->integral>1000)//积分限幅
pid->integral = 1000;
else if(pid->integral<-1000)
pid->integral = -1000;
// 计算PID输出 (位置式直接赋值)
pid->output = pid->Kp * error + pid->Ki * pid->integral + pid->Kd * error_rate;
// 保存上一次误差
pid->last_error = error;
//PWM限幅
if(pid->output>max_pwm)
pid->output=max_pwm;
else if(pid->output<-max_pwm)
pid->output=-max_pwm;
return pid->output;
}
3.语音交互节点
语音交互节点主要包括了语音识别、大模型处理和语音合成。因为目前大多数语音识别API都需要付费,因此使用Kaldi本地语音识别。大模型使用了不限次数免费的科大讯飞大模型API。语音合成可以使用免费的edge_tts、有道TTS、Kaldi本地TTS等。
(1)语音识别
因为目前大多数语音识别API都需要付费,因此使用sherpa_onnx库实现的本地语音识别,使用cpu推理模型:
class KaldiASR():
def __init__(self):
current_dir = os.path.dirname(os.path.realpath(__file__)) # 获取当前文件夹
model_path_name = os.path.join(current_dir,"..","model","sherpa-onnx-paraformer-zh-small-2024-03-09")
print("离线语音识别模型开始初始化...")
# 初始化语音识别
offline_asr.init(model_path_name)
print("离线语音识别模型初始化完成")
def audio_file_to_text(self, wav_name):
text = offline_asr.asr(wav_name)
#print("kaldi识别结果:",text)
return text
kaldi语音识别的代码如下:
def asr(*sound_files):
global args
global recognizer
global contexts_list
start_time = time.time()
streams = []
total_duration = 0
for wave_filename in sound_files:
samples, sample_rate = read_wave(wave_filename)
duration = len(samples) / sample_rate
total_duration += duration
if contexts_list:
s = recognizer.create_stream(contexts_list=contexts_list)
else:
s = recognizer.create_stream()
s.accept_waveform(sample_rate, samples)
streams.append(s)
recognizer.decode_streams(streams)
results = [s.result.text for s in streams]
end_time = time.time()
for wave_filename, result in zip(sound_files, results):
return f"{result}"
(2)大模型处理
使用了无限次免费的科大讯飞大模型API:
class WsProcess():
def __init__(self, wsParam):
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
self.ws = websocket.WebSocketApp(wsUrl, on_message=self.on_message, on_error=on_error, on_close=on_close, on_open=on_open)
self.answer = ""
# 收到websocket消息的处理
def on_message(self, message):
data = json.loads(message)
code = data['header']['code']
if code != 0:
print(f'请求错误: {code}, {data}')
self.ws.close()
#self.answer += data['header']['message']
else:
choices = data["payload"]["choices"]
status = choices["status"]
content = choices["text"][0]["content"]
self.answer += content
if status == 2:
self.ws.close()
def run(self, appid, domain, query):
self.ws.appid = appid
self.ws.query = query
self.ws.domain = domain
self.timeout = False
self.timer = threading.Timer(5, self.on_timeout) #5秒等待时间,如果大模型回复的内容多,就可能等待时间比较久
self.timer.start()
self.ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
self.timer.cancel()
if self.timeout:
print("大模型网络连接超时")
return "抱歉,我的网络好像卡住了"
else:
return self.answer
def on_timeout(self):
print("llm请求超时!")
self.timer.cancel()
self.timeout = True
self.ws.close()
(3)语音合成
目前使用免费的edge_tts(前一段时间挂了,升级到最新又能用了),或者国内的有道tts:
class YoudaoTranslate(BaseTranslate):
def __init__(self):
super(YoudaoTranslate, self).__init__()
self.home = 'https://dict.youdao.com/'
def get_tts(self, text, lan='', type_=2, *args, **kwargs):
""" 获取发音
:param text: 源文本
:param lan: 文本语言
:param type_: 发音类型
:return: 文本语音
"""
path = 'dictvoice'
params = {'audio': text, 'le': lan, 'type': type_}
response = self._get(path, params)
if response==None:
return None
if len(response.content)==0:
return None
return response.content
4.目标检测节点
目标检测节点采用了RK3566的NPU加速处理,推荐官方的模型仓库rknn_mode_zoo,官方已经支持了各类视觉和自然语言任务。本项目选用了速度较快的yolov6检测模型,模型部署的大致流程是先将pytorch转onnx,再将onnx转rknn,最后在开发板上读取rknn模型进行推理。
瑞芯微RK3566或RK3588支持NPU深度学习推理加速,官方提供的模型库链接:https://github.com/airockchip/rknn_model_zoo
目前模型库中已经支持了图像分类、目标检测、语义分割、实例分割、人脸关键点、车牌识别、文本识别OCR、机器翻译、图像文本匹配、语音识别、语音分类、文本转语音等各类深度学习任务。
下面介绍目标检测算法yolov6的模型部署过程,模型部署的大致流程是:
电脑python训练 –> .pt –> .onnx –> .rknn –> 开发板c++推理
(1)训练代码修改
先从官方github下载代码:
git clone https://github.com/meituan/YOLOv6.git
deploy/ONNX/export_onnx.py原始代码:
torch.onnx.export(model, img, f, verbose=False, opset_version=13,
training=torch.onnx.TrainingMode.EVAL,
do_constant_folding=True,
input_names=['images'],
output_names=['num_dets', 'det_boxes', 'det_scores', 'det_classes']
if args.end2end else ['outputs'],
dynamic_axes=dynamic_axes)
修改后,输出层改为3个,方便部署代码的后处理:
torch.onnx.export(model, img, f, verbose=False, opset_version=12,
training=torch.onnx.TrainingMode.EVAL,
do_constant_folding=True,
input_names=['images'],
output_names=['num_dets', 'det_boxes', 'det_scores', 'det_classes']
if args.end2end else ['output1','output2','output3'], #['outputs'],
dynamic_axes=dynamic_axes)
yolov6/models/heads/effidehead_distill_ns.py原始代码:
class Detect(nn.Module):
export = False
修改后:
class Detect(nn.Module):
export_rknn = True #导出rknn友好模型
export = False
原始代码:
def forward(self, x):
if self.training:
cls_score_list = []
reg_distri_list = []
reg_lrtb_list = []
修改后:
def _rknn_opt_head(self, x): #yolov6n,s会运行这个文件
output_for_rknn = []
for i in range(self.nl):
x[i] = self.stems[i](x[i])
reg_feat = self.reg_convs[i](x[i])
reg_output = self.reg_preds[i](reg_feat)
cls_feat = self.cls_convs[i](x[i])
cls_output = self.cls_preds[i](cls_feat)
cls_output = torch.sigmoid(cls_output) #npu支持sigmoid 消耗1ms以下
conf_max,_ = cls_output.max(1, keepdim=True) #此行实际会调用reducemax,npu支持max,但没有reducemax
#rknn推理仅cpu支持reducemax argmax sum等操作,并且argmax量化效果差
out = torch.cat((reg_output,conf_max,cls_output),dim=1) #4(reg)+1(max)+80(cls)
#out = torch.cat((reg_output,cls_output),dim=1) #4+80这种组合节约npu时间,但是后处理时间增加,cpu占用高
output_for_rknn.append( out )
return output_for_rknn
def forward(self, x):
if self.export_rknn:
return self._rknn_opt_head(x)
if self.training:
cls_score_list = []
reg_distri_list = []
reg_lrtb_list = []
代码修改完成后进行模型导出:
参考链接:https://github.com/meituan/YOLOv6/tree/main/deploy/ONNX
将img的高度设置为352,宽度设置为640,导出最小模型yolov6n.pt:
python ./deploy/ONNX/export_onnx.py \
--weights yolov6n.pt \
--img 352 640 \
--batch 1 \
--simplify
yolov6n.onnx模型可视化,使用Netron工具打开模型:
可以看到模型输入图像尺寸为1x3x352x640:
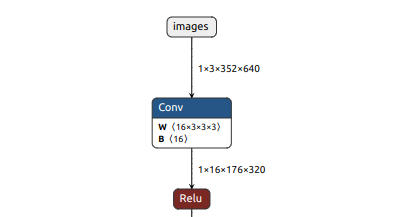
模型其中一个分支输出尺寸为1x85x11x20:
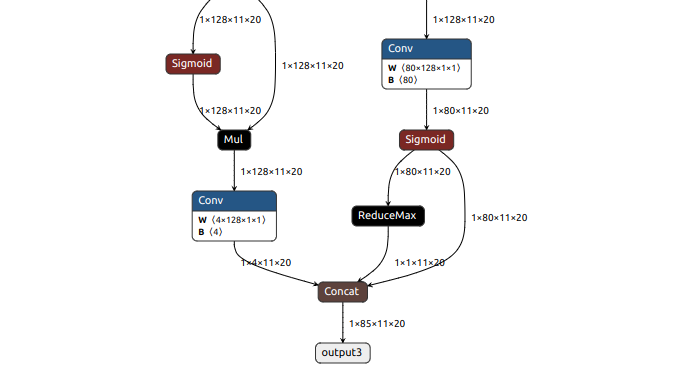
(2)模型转换
模型转换之前需要在电脑安装rknn-toolkit2,大致转换代码如下:
def export_rknn_inference(img):
# Create RKNN object
rknn = RKNN(verbose=False)
# pre-process config
print('--> Config model')
rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]],target_platform='rk3566')
print('done')
# Load ONNX model
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export RKNN model
print('--> Export rknn model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
# Init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime()
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
# Inference
print('--> Running model')
outputs = rknn.inference(inputs=[img])
rknn.release()
print('done')
return outputs
转换后得到yolov6n.rknn文件,使用python接口推理可以得到绘制了检测结果的图片:

也可以用Netron工具可视化查看:
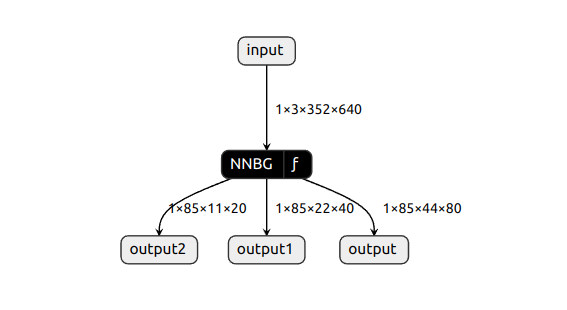
输出层:
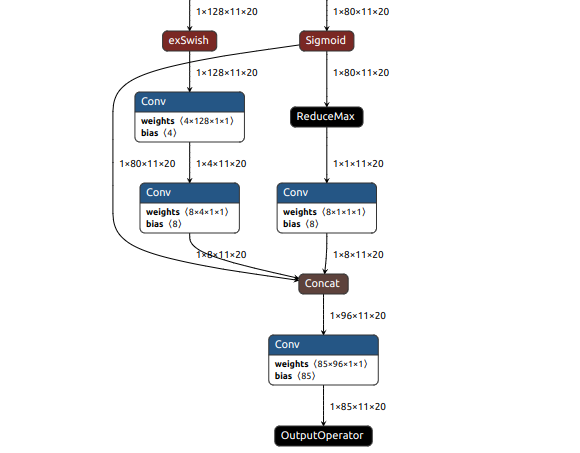
(3)模型部署代码
模型部署代码运行在开发板上,使用C++代码实现推理,主要修改后处理代码:
static int process_float(float *input, int grid_h, int grid_w, int height, int width, int stride,
std::vector<float> &boxes, std::vector<float> &objProbs, std::vector<int> &classId,
float threshold, int32_t zp, float scale,int OBJ_CLASS_NUM)
{
int validCount = 0;
int grid_len = grid_h * grid_w;
//printf("hxw %dx%d %dx%d %d\n",grid_h,grid_w,height,width,stride);
for (int i = 0; i < grid_h; i++)
{
for (int j = 0; j < grid_w; j++)
{
if( input[4 * grid_len + i*grid_w + j] < threshold )//4+1+80
{
continue;//这一步可以节约大量后处理时间,并且减少CPU占用
//但是将ReduMax放在模型推理中完成,模型推理也调用的是CPU,所以CPU会在推理时偏高
}
//4+1+80 or 4+80
float *in_ptr = input + i*grid_w + j;
//float prob_max = in_ptr[4 * grid_len];
float prob_max = in_ptr[5 * grid_len];
int maxClassId = 0;
for (int c = 1; c < OBJ_CLASS_NUM; c++)
{
//float prob = in_ptr[(4 + c) * grid_len];
float prob = in_ptr[(5 + c) * grid_len];
if (prob > prob_max)
{
maxClassId = c;
prob_max = prob;
}
}
if (prob_max >= threshold)
{
float box_x = j + 0.5 - in_ptr[0 * grid_len];
float box_y = i + 0.5 - in_ptr[1 * grid_len];
float box_x2 = j + 0.5 + in_ptr[2 * grid_len];
float box_y2 = i + 0.5 + in_ptr[3 * grid_len];
float box_w = box_x2-box_x;
float box_h = box_y2-box_y;
//printf("prob=%f\n",maxClassProbs);
// objProbs.push_back(maxClassProbs);
// classId.push_back(maxClassId);
objProbs.push_back(prob_max);
classId.push_back(maxClassId);
boxes.push_back(box_x*stride);
boxes.push_back(box_y*stride);
boxes.push_back(box_w*stride);
boxes.push_back(box_h*stride);
validCount++;
}
}
}
return validCount;
}
5.SLAM和导航节点
最后是slam和导航节点,slam和导航基本都是用ROS自带的功能包,只需要根据自己机器人情况修改配置文件,例如调整机器人的尺寸配置,修改机器人的最大速度限制等。
(1)启动功能包
在小白机器人上启动SLAM和导航的命令如下:
cd ~/newbot_ws
source devel/setup.bash
roslaunch robot_navigation blank_map_move_base.launch #空地图下测试路径规划(map坐标系和odom坐标系永远一致)
#先要打开雷达
roslaunch robot_navigation robot_slam.launch #SLAM建图测试
cd maps && rosrun map_server map_saver -f map #进入robot_navigation包里的maps目录,执行map_server保存地图
roslaunch robot_navigation robot_navigation.launch #加载上一部保存的地图、定位和路径规划测试
电脑上可视化建图和导航效果:
$ rviz #在电脑上执行,打开pkg_launch/rviz/robot.rviz文件可视化建图和导航结果
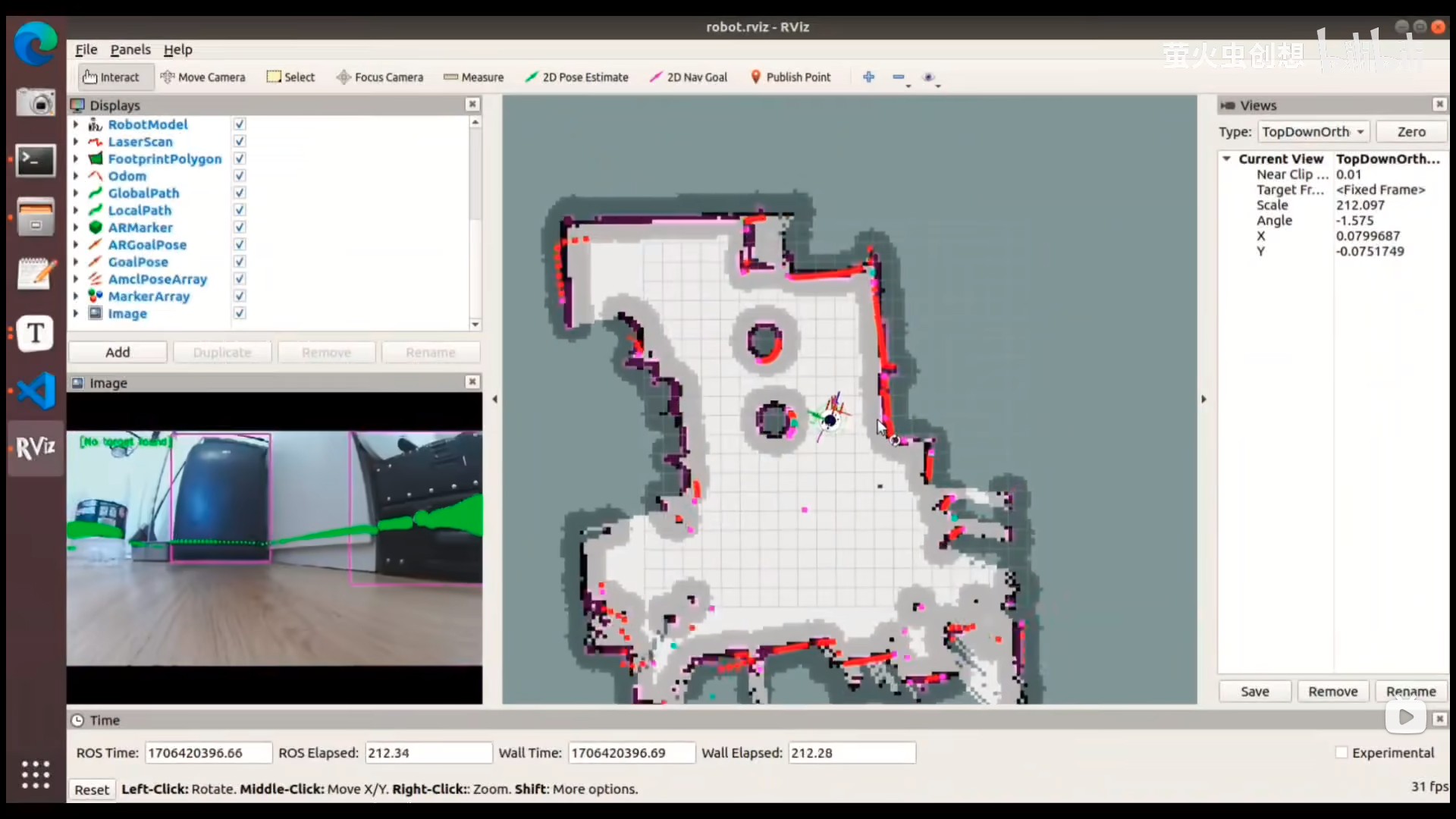
(2)修改配置文件
以下改动量比较大的两个配置文件,首先要调整机器人的尺寸配置,还需要修改机器人的速度限制:
# newbot_ws/src/robot_navigation/config/robot/costmap_common_params.yaml配置文件:
obstacle_range: 3.0 #障碍物范围 机器人只会更新其地图包含距离移动基座obstacle_range米以内的障碍物的信息
raytrace_range: 3.5 #光线追踪范围 机器人将尝试清除raytrace_range米外的空间,在代价地图中清除raytrace_range米外的障碍物
#footprint: [[-0.07, -0.06], [-0.07, 0.06], [0.05, 0.06], [0.05, -0.06]]
robot_radius: 0.07 #圆形机器人半径 直径12cm,半径6cm
inflation_radius: 0.2 #1.0 #膨胀半径 如果机器人经常撞到障碍物就需要增大该值!!!!!,若经常无法通过狭窄地方就减小该值!!!!!
cost_scaling_factor: 3.0 #3.0 # exponential rate at which the obstacle cost drops off(default: 10)
map_type: costmap
observation_sources: scan
scan: {sensor_frame: laser_link, data_type: LaserScan, topic: scan, marking: true, clearing: true}
#marking表示是否可以使用该传感器来标记障碍物
#clearing表示是否可以使用该传感器来清除障碍物标记为自由空间
#参数参考了github turtlebot3代码
#https://github.com/ROBOTIS-GIT/turtlebot3/tree/master/turtlebot3_navigation/param/costmap_common_params_burger.yaml
DWAPlannerROS:
# newbot_ws/src/robot_navigation/config/robot/dwa_local_planner_params.yaml配置文件:
# Robot Configuration Parameters
max_vel_x: 0.10 #0.22 #机器人的最大 x 速度 默认值:0.55
min_vel_x: -0.10 #-0.22 #机器人的最小x速度(以m / s为单位),向后运动为负 默认值:0.0
max_vel_y: 0.0 #机器人的最大 y 速度
min_vel_y: 0.0 #机器人的最小 y 速度
# The velocity when robot is moving in a straight line
max_vel_trans: 0.10 #0.22 #机器人最大平移速度的绝对值 默认值:0.55
min_vel_trans: 0.05 #0.11 #机器人最小平移速度的绝对值 默认值:0.1
max_vel_theta: 2.0 #2.75 #机器人最大旋转速度的绝对值 默认值:1.0
min_vel_theta: 1.0 #1.37 #机器人最小旋转速度的绝对值 默认值:0.4
acc_lim_x: 2.5 #机器人的 x 加速度极限 默认值:2.5
acc_lim_y: 0.0 #机器人的 y 加速度极限 默认值:2.5
acc_lim_theta: 3.2 #机器人的旋转加速度极限 默认值:3.2
# Goal Tolerance Parameters
xy_goal_tolerance: 0.05 #实现目标时控制器在 x 和 y 距离内的公差 默认值:0.10
yaw_goal_tolerance: 0.17 #控制器在实现目标时偏航/旋转时的弧度公差 默认值:0.05
latch_xy_goal_tolerance: false ##如果被锁定,如果机器人到达目标xy位置,它将简单地在原地旋转,即使它最终超出了目标公差 默认值:假
# Forward Simulation Parameters
sim_time: 2.0 #1.5 #向前模拟轨迹的时间 默认值:1.7 太小不停地拐弯,轨迹不流畅;太大走大圈和轨迹不符合
vx_samples: 6 #20 #探索 x 速度空间时要使用的样本数 默认值:3
vy_samples: 0 #探索 y 速度空间时要使用的样本数 默认值:10
vth_samples: 40 #40 #探索θ速度空间时要使用的样本数量 默认值:20
controller_frequency: 10.0 #调用此控制器的频率(以 Hz 为单位) 默认值:20.0
# Trajectory Scoring Parameters
path_distance_bias: 32.0 #32.0 #控制器应保持与给定路径的接近程度的权重 默认值:32.0 #本地规划器与全局路径保持一致的权重 较大的值将使本地规划器更倾向于跟踪全局路径
goal_distance_bias: 20.0 #20.0 #控制器应尝试达到其本地目标的权重也控制速度 默认值:24.0 #会使机器人与全局路径的匹配度偏低
occdist_scale: 0.01 #0.02 #控制器应尝试避免障碍物的权重 默认值:0.01
forward_point_distance: 0.325 #从机器人中心点到放置一个附加得分点的距离 默认值:0.325
stop_time_buffer: 0.2 #机器人在碰撞前必须停止的时间量,以使轨迹在几秒钟内被视为有效 默认值:0.2
scaling_speed: 0.25 #开始缩放机器人占地面积的速度的绝对值,以 m/s 为单位 默认值:0.25
max_scaling_factor: 0.2 #将机器人的占地面积缩小到以下列的最大系数 默认值:0.2
# Oscillation Prevention Parameters
oscillation_reset_dist: 0.05 #在振荡标志重置之前,机器人必须以米为单位行进多远 默认值:0.05
# Debugging
publish_traj_pc : true
publish_cost_grid_pc: true
holonomic_robot: false #是否为全向机器人 值为false时为差分机器人; 为true时表示全向机器人
#http://wiki.ros.org/dwa_local_planner?distro=noetic
#参数参考:
#https://blog.csdn.net/weixin_42005898/article/details/98478759
#导航调优指南.pdf
#https://blog.csdn.net/luohuiwu/article/details/92985584